从零开始的Python学习
+
HTML 标签
<a> 标签 (Anchor Tag)
标签用于定义超链接(hyperlink),允许用户从一个网页跳转到另一个网页、同一页面的不同位置、文件下载地址、电子邮件地址等。
主要属性:
href(Hypertext Reference): 用于指定链接的目标 URL 或锚点。- 外部链接:
href="https://www.example.com" - 内部链接 (同一网站的不同页面):
href="/about.html"或href="about.html"(取决于文件路径) - 锚点链接 (同一页面的不同部分):
href="#section2"(需要配合页面中具有id="section2"的元素使用) - 电子邮件链接:
href="mailto:user@example.com" - 电话链接:
href="tel:+1234567890" - JavaScript 代码 (不推荐直接在
href中使用):href="javascript:alert('Hello!')"(通常更好的做法是使用事件监听器)
- 外部链接:
target: 指定在何处打开链接的文档。_blank: 在一个新的窗口或标签页中打开链接。_self: 在当前窗口或标签页中打开链接 (默认值)。_parent: 在父框架中打开链接。_top: 在最顶层的框架集中打开链接。<framename>: 在指定的框架中打开链接。
rel(Relationship): 描述当前文档与被链接文档之间的关系。常用的值包括:noopener: 防止新标签页中的网站访问你的窗口对象 (window.opener),提高安全性。通常与target="_blank"一起使用。noreferrer: 阻止浏览器在 HTTP 请求头中发送Referer信息。通常与target="_blank"一起使用。nofollow: 告诉搜索引擎不要将链接权重传递给目标页面,常用于评论或用户生成的内容中的链接。
download: 提示浏览器下载链接的资源,而不是导航到它。可以指定下载的文件名,例如download="my-document.pdf"。type: 指定链接文档的 MIME 类型,例如type="application/pdf"。
用法示例:
HTML
1 | <a href="https://www.google.com" target="_blank">访问 Google</a> |
<span> 标签
<span> 标签是一个内联容器,用于在文本中标记一小段内容,以便可以使用 CSS 或 JavaScript 对其进行样式化或操作。<span> 标签本身没有任何语义上的含义,它只是一个通用的行内元素。
主要特点:
- 内联元素:
<span>元素默认是内联的,这意味着它不会打断正常的文本流,并且只占据它包含的内容所需的宽度。 - 无语义: 它本身不表示任何特定的内容类型或结构。
- 通常与 CSS 和 JavaScript 配合使用: 通过为
<span>元素添加class或id属性,可以方便地使用 CSS 来设置样式,或者使用 JavaScript 来进行动态操作。
用法示例:
HTML
1 | <p>这是一段包含 <span style="color: red;">红色</span> 文字的段落。</p> |
<img> 标签 (Image Tag)
标签用于在 HTML 文档中嵌入图像。它是一个自闭合标签,意味着它没有闭合标签 ()。
主要属性:
src(Source):这是
标签最主要的属性,用于指定图像文件的路径 (URL)。可以是相对路径或绝对路径。
- 相对路径:
src="images/logo.png"(假设images文件夹与当前 HTML 文件在同一目录下) - 绝对路径:
src="https://www.example.com/images/banner.jpg"
- 相对路径:
alt(Alternative Text): 提供图像的替代文本描述。当图像无法加载时,或者对于屏幕阅读器等辅助技术,alt属性的内容会被显示或朗读。这是一个非常重要的属性,有助于网站的可访问性和 SEO。width和height: 指定图像的宽度和高度 (以像素为单位)。建议设置这两个属性,以防止页面在图像加载时发生布局跳动。loading:控制图像的加载方式,可以提高页面性能。
lazy: 延迟加载图像,直到它们接近视口时才加载。eager: 立即加载图像 (默认值)。
srcset: 允许为不同的屏幕尺寸或设备像素比率提供不同的图像版本,实现响应式图像。sizes: 与srcset属性一起使用,定义在不同的屏幕条件下图像的预期宽度。crossorigin: 用于处理跨域图像的加载。
用法示例:
HTML
1 | <img src="logo.png" alt="公司的标志" width="150" height="50"> |
总结:
<a>用于创建超链接,实现页面间的跳转或与外部资源的连接。<span>是一个无语义的内联容器,常用于配合 CSS 和 JavaScript 对文本进行样式化或操作。<img>用于在 HTML 文档中嵌入图像,并提供了描述、尺寸和加载控制等属性。
yield关键字
yield关键字的引入是为了实现生成器generator,生成器是一种特殊类型的函数,以更简洁,更节省内存的方式来生成一个序列,不需要一次性将所有的值都存储在内存中(和return类比)
推导式
常用来生成字典,列表,序列等
1 | # 列表推导式 |
PyMySQL 进行数据库操作
Scrapy框架
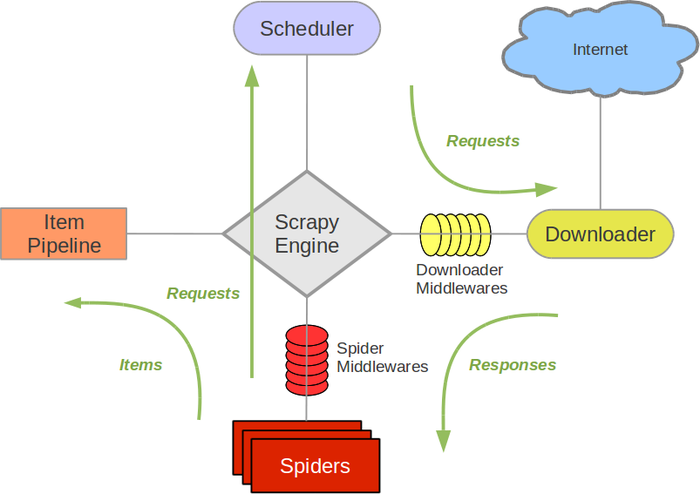
| 组件 | 对应爬虫三大流程 | Scrapy 项目是否需要修改 |
|---|---|---|
| 引擎 | 大脑 | 无需修改,框架已写好 |
| 调度器 | 接受engine的请求,按照先后顺序压入队列中,去除重复请求 | 无需修改,框架已写好 |
| 下载器 | 获取网页 (request 库) | 无需修改,框架已写好 |
| 爬虫器 | 解析网页 (BeautifulSoup 库) | 需要 |
| 管道 | 存储数据 (存入 csv/txt/MySQL 等) | 需要 |
| 下载器中间件 | 获取网页 - 个性化部分 | 一般不用 |
| 爬虫器中间件 | 解析网页 - 个性化部分 | 一般不用 |
安装和使用
1 | pip install scrapy |
简单的案例
1 | # 这里同样引用了scrapy中的pipline midedlewares等 |
1 | # Define here the models for your scraped items |
添加爬取页面详细信息
1 | # 这里同样引用了pipline midedlewares等 |
1 | # Define your item pipelines here |
- 第二次爬取时候遇到了(302) 重定向,需要加入反爬虫机制
自定义中间件&随机代理IP
Downloader Middleware:The downloader middleware is a framework of hooks into Scrapy’s request/response processing. It’s a light, low-level system for globally altering Scrapy’s requests and responses.
遇到问题&解决方案
网站中的重定向30X
- 修改下User-Agnet,,尝试使用本地真实UserAgnet
- 查看start_requests()和parse()函数,在parse()函数中输出self.logger.info进行debug
Ajax动态加载
网页处理时候选择右键查看源码与控制台HTML不同的情况

